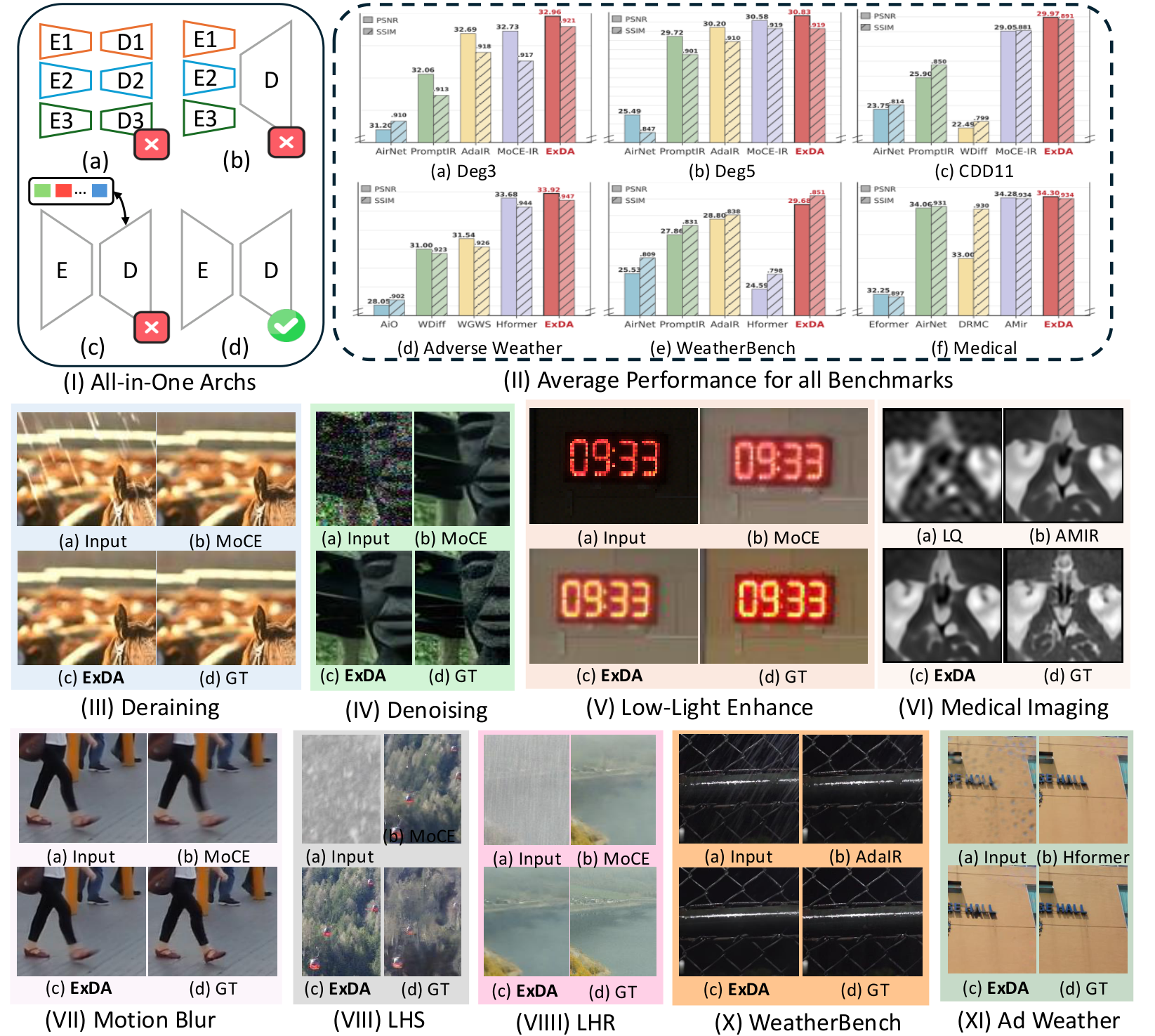
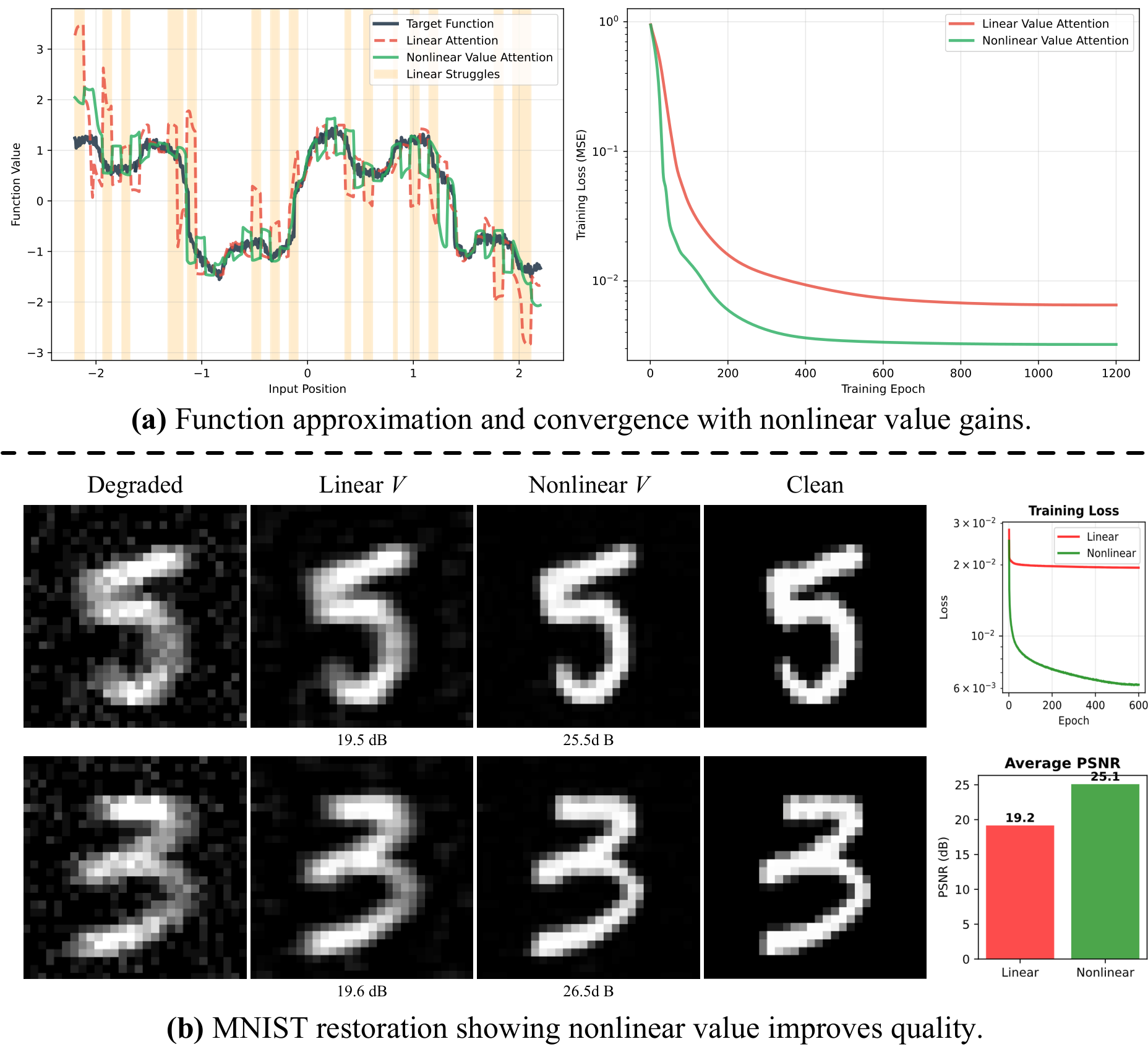
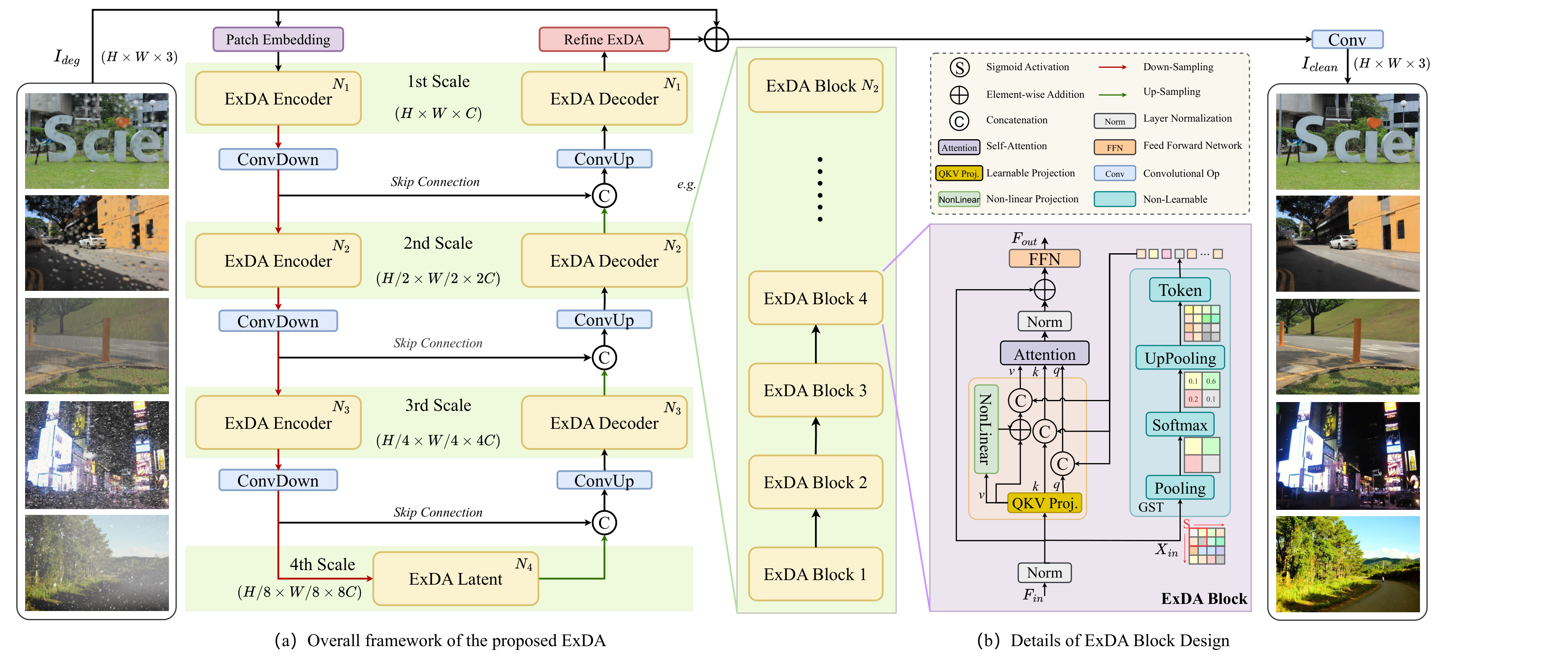
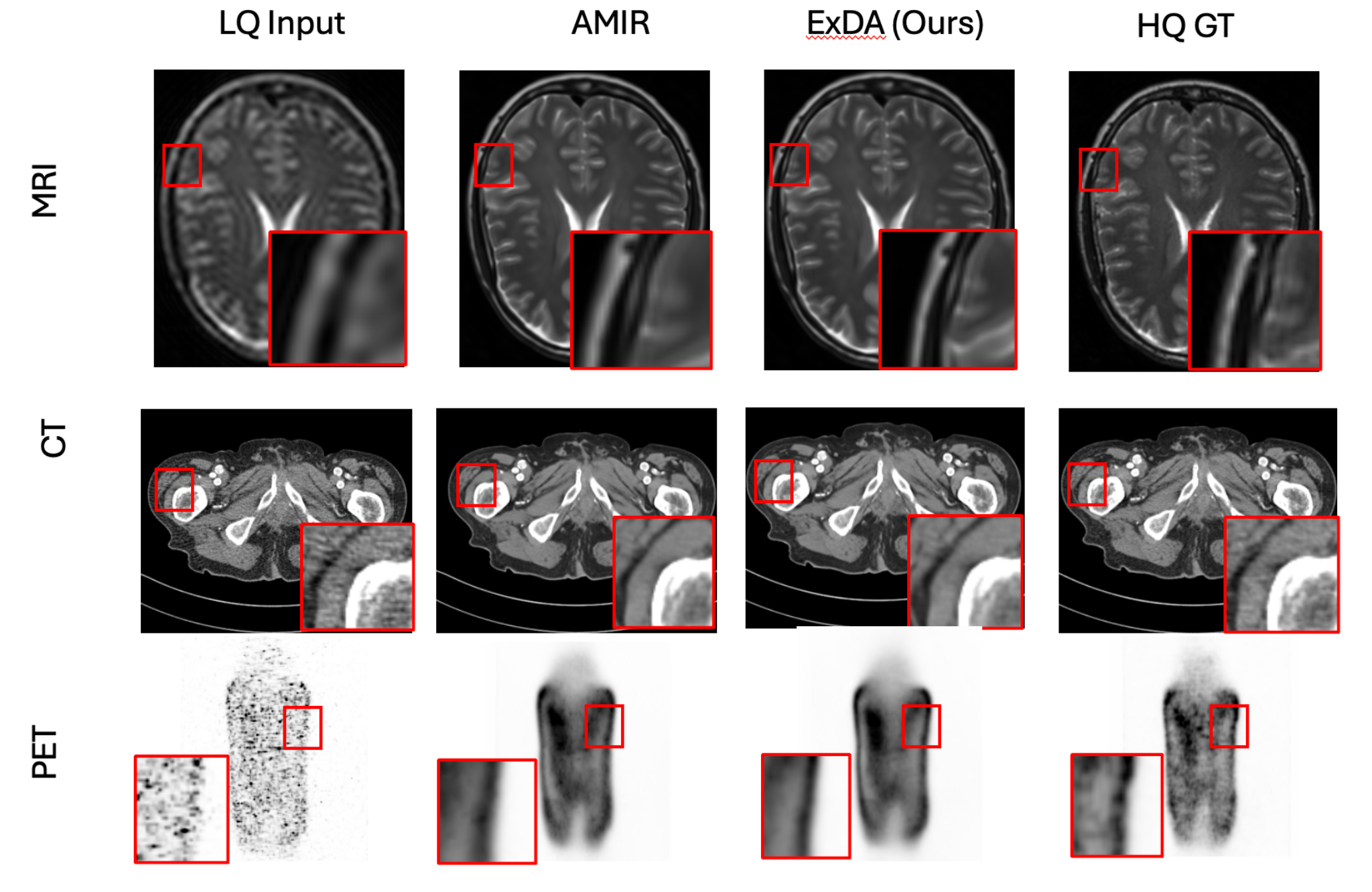
All-in-one image restoration (IR) aims to recover high-quality images from di- verse degradations, which in real-world settings are often mixed and unknown. Unlike single-task IR, this problem requires a model to approximate a family of heterogeneous inverse functions, making it fundamentally more challenging and practically important. Although recent focus has shifted toward large multimodal models, their robustness still depends on faithful low-level inputs, and the princi- ples that govern effective restoration remain underexplored. We revisit attention mechanisms through the lens of all-in-one IR and identify two overlooked bottle- necks in widely adopted Restormer-style backbones: (i) the value path remains 1 Published as a conference paper at ICLR 2026 purely linear, restricting outputs to the span of inputs and weakening expressivity, and (ii) the absence of an explicit global slot prevents attention from encoding degradation context. To address these issues, we propose two minimal, backbone- agnostic primitives: a nonlinear value transform that upgrades attention from a selector to a selector–transformer, and a global spatial token that provides an ex- plicit degradation-aware slot. Together, these additions improve restoration across synthetic, mixed, underwater, and medical benchmarks, with negligible overhead and consistent performance gains. Analyses with foundation model embeddings, spectral statistics, and separability measures further clarify their roles, positioning our study as a step toward rethinking attention primitives for robust all-in-one IR. Project page is at https://amazingren.github.io/projects/ExDA/.