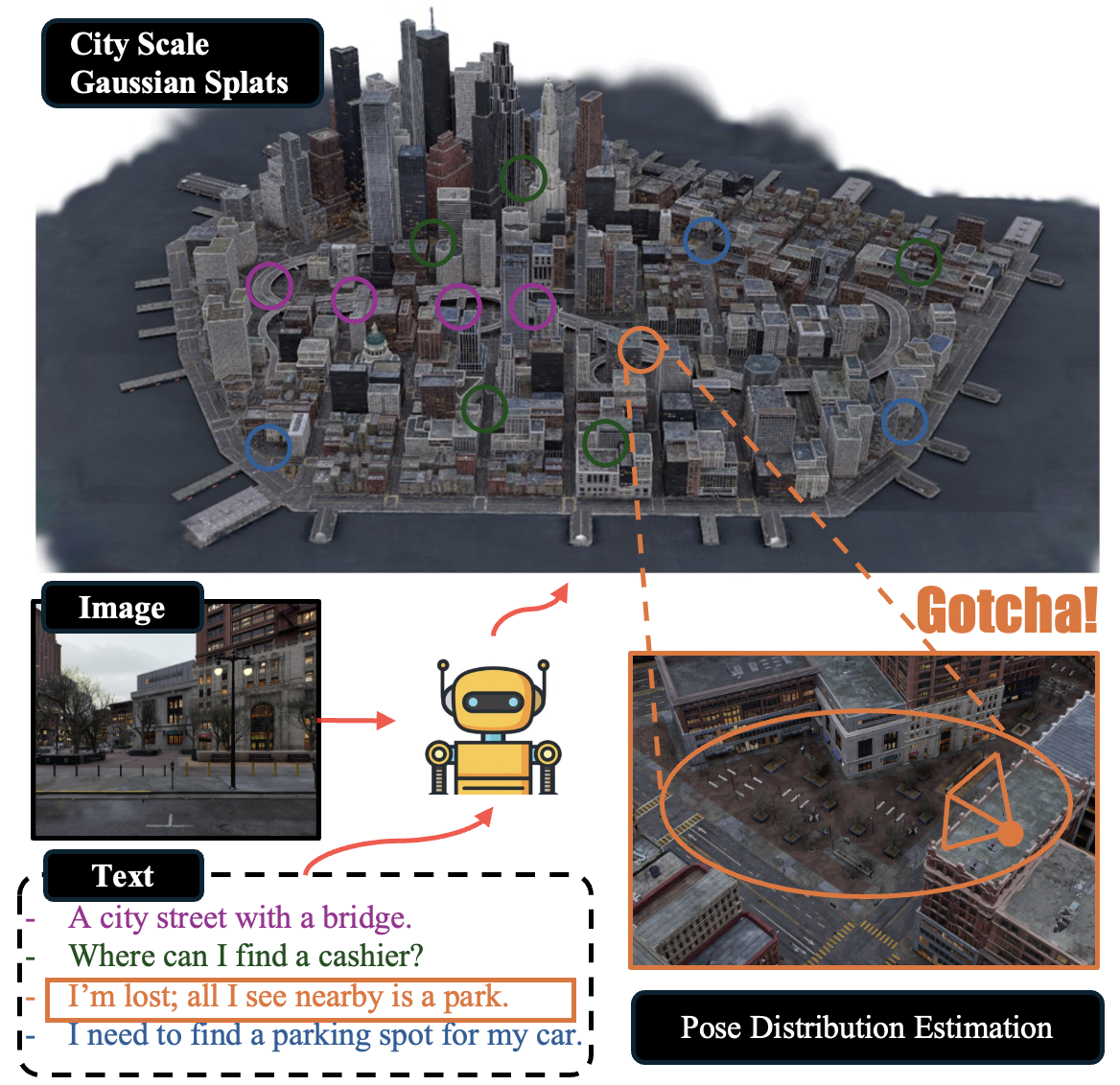
Localizing textual descriptions within large-scale 3D scenes presents inherent ambiguities, such as identifying all traffic lights in a city. Addressing this, we introduce a method to generate distributions of camera poses conditioned on textual descriptions, facilitating robust reasoning for broadly defined concepts.
Our approach employs a diffusion-based architecture to refine noisy 6DoF camera poses towards plausible locations, with conditional signals derived from pre-trained text encoders. Integration with the pretrained Vision-Language Model, CLIP, establishes a strong linkage between text descriptions and pose distributions. Enhancement of localization accuracy is achieved by rendering candidate poses using 3D Gaussian splatting, which corrects misaligned samples through visual reasoning.
We validate our method's superiority by comparing it against standard distribution estimation methods across five large-scale datasets, demonstrating consistent outperformance.
@article{ma2025cityloc,
title={CityLoc: 6 DoF Localization of Text Descriptions in Large-Scale Scenes with Gaussian Representation},
author={Ma, Qi and Yang, Runyi and Ren, Bin and Konukoglu, Ender and Van Gool, Luc and Paudel, Danda Pani},
journal={arXiv preprint arXiv:2501.08982},
year={2025}
}